
第一节课主要讲了模式识别概论。
主要内容
-
贝叶斯决策理论
-
参数估计
-
非参数技术
-
线性判别函数
由分布函数到判别函数。
-
多层神经网络
-
非测量方法
-
无监督学习与聚类
-
独立于算法的技术
没有一个算法是最佳算法。算法是与具体问题关联的。
考核
闭卷考试
参考书籍
模式识别系统的部件
-
sensing devices 传感设备
包括麦克风 , 摄像头等等(本质是环能器) 。
-
preprocessing 预处理
分割、聚合(如鱼厂分类鱼时,要将摄像头得到的图片进行切分,从中取出鱼的部分;如果一条鱼被其他鱼挡住了,切分之后,还需要合并被分开的部分。)
-
Features Extracting 特征抽取
特征抽取可以认为是从高维空间降维到低维空间的过程。 (我觉得这句话非常有意义。)
-
classifier 分类器
-
Decision Theory 判决理论
对称(损失相同)
非对称(损失加权)
-
Decision Boundary 决策边界
一维 -> 点 , 二维 -> 线 , 三维 -> 面 , 高维 -> 超平面
-
Generalization 泛化
分类器的目标是良好地分类未知的样本(unseen objects)。
将分类器对训练集的分类效果叫做拟合。如果在训练分类器时 ,
-
模型参数过多(模型过于复杂)
-
训练集样本少
将会导致过拟合的情况。其表现是在训练集上分类效果极佳,但是在预测(或者在开发集)时效果很差。模型过拟合训练集,则其泛化能力将会降低。则其分类未知数据的能力就差。
在训练样本数量一定的情况下,我们可以通过减少模型复杂度(减少参数、正则化)来防止过拟合。
因而,这是一个模型复杂度与训练集上分类效果的折衷(Trade-Off)。
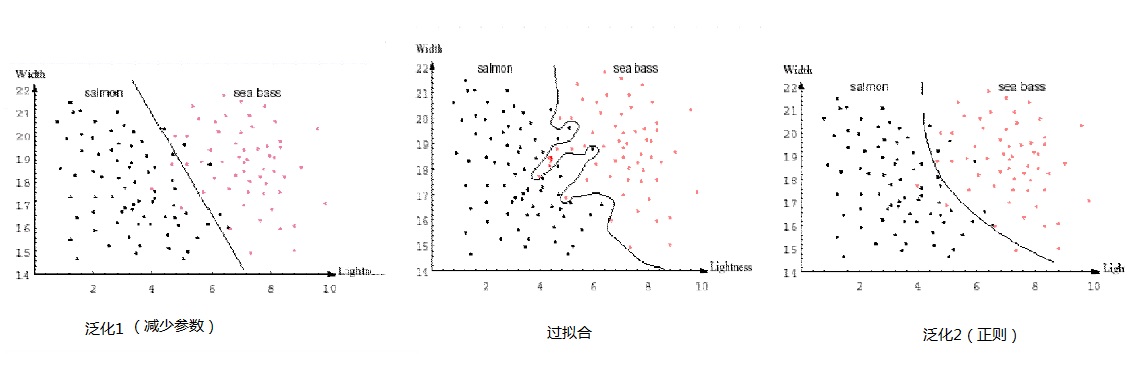
最后,我们可以通过开发集做泛化能力测试。
-
-
-
post processing 后处理
在上下文中考虑分类结果(考虑序列间的关系,代价调整 —— 这个似乎也可以放在分类器中)
本课程主要着重于分类器部分。